
空のメール画面でカーソルが点滅している。言いたいことはわかっている。ただ、入力する気になれない。
Macのディクテーションは2012年から存在していて、多くの人は何年も前にあきらめてしまった。それを変えたのが、ここ18か月のMac向けAI音声ディクテーションだ。「マイクに向かって話すと誤字の壁が現れる」という古い体験は、いつの間にか「本当に書いているような感覚」に置き換わっていた。
ほとんどの記事が触れない部分がある。難しいのはもはや書き起こしではない。それはすでに解決済みだ。変わったのはその上のレイヤー、つまりあなたの取り留めのない発話を画面に出る前に整った文章へ変える処理だ。この記事では、話し始めた瞬間から下書きに整った文章が届く瞬間までに、Macの中で実際に何が起きているのかを順を追って見ていく。
Macのディクテーションがようやく実用的に感じる理由
ディクテーションに戻ってくる人が増えている理由は、2つの数字で説明できる。平均的な人のタイピング速度は1分あたり約40語。話す速度は約150語。タイピングで1語打つ間に、口では4語ほど話せる計算だ。
とはいえ、本当の問題は速度ではなかった。問題は出力だ。昔のディクテーションは、「えーと」も言い直しも「いや、今のなし」もそのまま文字に起こしてくれた。30秒分の口述で稼いだ時間を、後片付けに90秒費やすことになる。
最近のAIディクテーションアプリは、ここに2つ目の工程を加えてこの問題を解決した。まず従来どおり音声を書き起こす。その後、整った編集者のように書き直す言語モデルに渡す。フィラーは削除。文法は修正。文末はきちんと締める。画面に文字が現れたときには、調子のいい日に自分が書いたような文章になっている。
MacのAI音声ディクテーションを支える5つのステップ
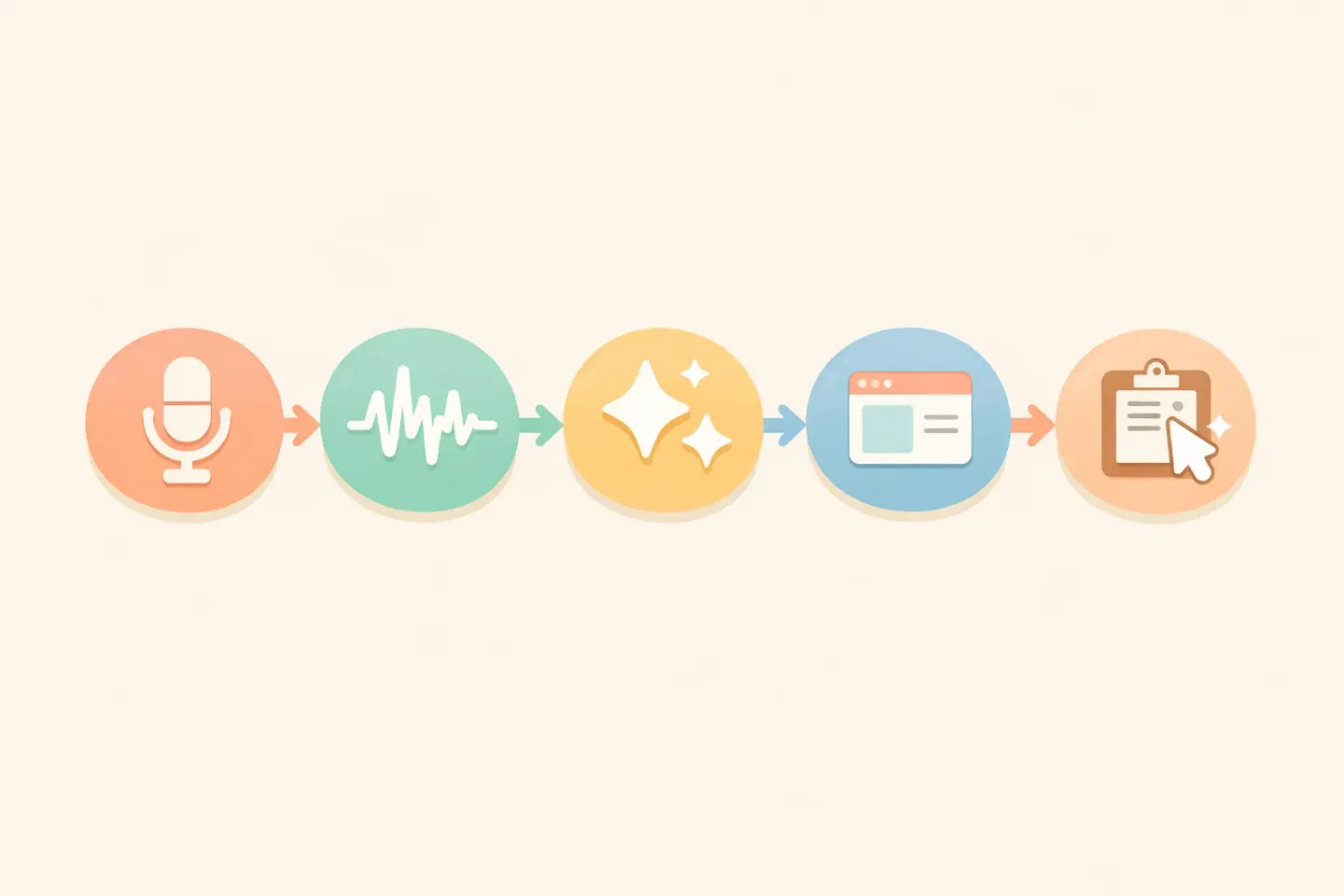
パイプラインは短い。5ステップで、その大半は目に見えない。 1. キャプチャ。Macがあなたの声を拾う。 2. 書き起こし。音声を生のテキストに変える。 3. 整文。AIモデルが生テキストを磨き上げる。 4. コンテキスト適用。書き込み先に合わせて文体を調整する。 5. 配信。整った文章がカーソル位置に届く。
それぞれのステップに専用のモデル、トレードオフ、そして失敗しやすいポイントがある。一つずつ理解しておく価値がある。
ステップ1:キャプチャ。Macはどう声を拾うのか
ここは凝った仕組みではない。ホットキー(FN、Option+Space、あるいはアプリが採用しているもの)を押すと、マイクが聞き始める。アプリは音声をメモリに記録する。形式は16ビット・16kHzが一般的で、これは書き起こしモデルが想定する形式だ。
最近のMacディクテーションアプリの多くは、録音の開始・停止に音声アクティビティ検出を使わない。代わりにホットキーを使う。押している間だけ話し、離せば止まる。理由は信頼性だ。カフェのオープンマイクで音声検出に頼るのはコイントスに近い。キー入力ならそうはならない。
キャプチャ中には、見えないところでいくつかのことが起きている。音声はバッファリングされ、多くの場合はAppleの組み込み音声フレームワークでノイズが抑制され、チャンクに分割される。チャンクサイズ(通常30秒)を超えて話すと、アプリは送信前に録音を分割することもある。
ステップ2:書き起こし。Whisperが音を言葉に変える方法
ここで多くのMac向けAIディクテーションアプリは1つの技術に集約される。それがOpenAIのWhisperモデルだ。Whisperは99言語、約500万時間の音声で学習された音声認識システムだ。最新のlarge-v3はクリーンな英語音声で約2.7%、ノイズのある実環境録音で8〜12%の単語誤り率を達成している。
わかりやすく言えば、自然に話すだけで92〜97%の単語が初期設定で正しく書き起こされる。これはAppleの旧来のディクテーションエンジンとはまったく別格の精度で、サードパーティ製アプリが台頭した理由でもある。
Whisperが音声に対しておこなう処理は、おおむね次のとおりだ。 - 録音を30秒のチャンクに切り分ける。 - 各チャンクをスペクトログラム、つまり周波数と時間にわたる音の視覚的表現に変換する。 - そのスペクトログラムを、音響パターンを単語に対応付けるよう学習したニューラルネットワークに入力する。 - 言語、句読点、文の区切りも併せて予測する。
モデルはMac上でローカルに動かすこともできるし(Apple Siliconなら余裕で動く)、クラウドで動かすこともできる。ローカルはプライバシーが保たれ、オフラインでも使える。クラウドは古いハードでも高速で、より大きなモデルにも対応する。多くのアプリで選択可能だ。
このステップで得られるのは生の書き起こしだ。句読点付きで、ほぼ正確で、たいてい少し荒削り。Appleの組み込みディクテーションはここで終わる。本当に面白いアプリは、ここで止まらない。
ステップ3:整文。すべてを変えたレイヤー
Macのディクテーションを「まあ使える」から「もう何週間もメールを打っていない」に変えたのが、このステップだ。
書き起こしのあと、生テキストは言語モデル(多くはGPT-4クラスかClaude)に送られ、こんな指示が添えられる。 ``` これを洗練されたプロフェッショナルな文章に書き直してください。フィラーや言い直しは削除し、意味は保ち、何も付け足さないでください。 ```
実際の例を見てみよう。
話した内容
*「えーと、その、先週の提案の件で、ちょっとフォローしたくて。なんていうか、オプション2で進めるのがいいんじゃないかなって思うんだけど?うん、オプション2で。あの、契約書を金曜までに送ってもらえる?」*
クリップボードに届く内容
*「先週ご提案いただいた件のフォローアップです。オプション2で進めたいと考えています。金曜日までに契約書をお送りいただけますか。」*
意味は同じ。読み心地はまったく別物。しかもこれが2秒以内で起きる。
ここは試してみるまで言葉では伝わりにくい部分だ。自分の話し方を気にしなくなる。話しながらの自己編集をやめる。同僚に話すように、ただ言いたいことを口にすればいい。出てくるのは、時間さえあれば自分が書いたであろうバージョンだ。
すでにディクテーションは使っているが、あとの手直しに時間を取られているなら、そのギャップを埋めるのがVoicrだ。FNを押して、好きなように話せば、クリップボードには整った文章が届く。やり直しも、「あの一文だけ直さないと」もなく、貼り付けるだけのきれいなテキストが手に入る。
ステップ4:コンテキスト認識。アプリごとに変わる文体
これは比較的新しいステップだ。そして、優秀なMacディクテーションアプリと、ただ動くだけのアプリを分ける部分でもある。
丁寧でフォーマルなトーンは、顧客向けメールには合う。同僚への Slack メッセージでは違和感がある。コードのコメントとしては論外だ。優れたディクテーションアプリは、いま使っているアプリを判断して文体を調整する。
仕組みはシンプルだ。アプリはどのアプリケーションがフォーカスを持っているかを読み取る。そのアプリ用に保存されたスタイルルールを呼び出す。そしてそのルールを整文モデルに渡すプロンプトに織り込む。
Slack用のルールはたとえばこうだ。 ``` カジュアルで簡潔に。堅苦しい表現は使わない。短縮形を使う。短い文を1〜2文まで。 ``` メール用ならこうなる。 ``` プロフェッショナルなトーンで書く。完結した文で構成する。内容に応じて挨拶と結びを添える。 ```
同じ音声入力でも、開いているウィンドウによってまったく違う出力になる。何かを切り替える必要はない。ただ話せば、それに合ったトーンで出てくる。
ステップ5:配信。テキストを必要な場所に届ける方法
最後のステップは、最も洗練に時間がかかった部分だ。整った文章はある。では、それをどうやってアクティブな入力欄に届けるのか。
一般的なアプローチは2つある。 1. クリップボード経由。 整ったテキストをクリップボードにコピーし、macOSのアクセシビリティAPI経由でペースト(Cmd+V)を発火する。高速で信頼性が高く、ほぼあらゆるアプリで動く。 2. キーストローク注入。 AppleScriptや同じアクセシビリティフレームワークを使って、文字を1文字ずつタイピングするように再現する。遅いが、ペーストをブロックするアプリ(一部のオンラインバンキング、リモートデスクトップ、パスワードマネージャー)でも動く。
多くのアプリは既定でクリップボード経由を選び、必要なときだけキーストローク注入にフォールバックする。あなたの目線では、ホットキーを離してから約0.5秒後にカーソル位置にテキストが現れる。アプリの切り替えも、コピー操作も、確認も要らない。
ローカル処理とクラウド処理。実際には何が起きているのか
よく聞かれる質問がある。私の声はどこへ行くのか?
現実的な選択肢は2つある。ローカル処理はWhisperモデルをMac上で動かす。音声がデバイスから出ることはない。Apple Silicon(M1以降)であれば、ローカルのWhisperでもリアルタイム・ディクテーションに十分な速度が出る。遅延はたいてい1秒未満だ。トレードオフとして、整文ステップは通常クラウドのモデルに頼ることになる。700億パラメータの言語モデルをノートPCでローカルに動かすのは現実的ではないからだ。一部のアプリは、品質を多少落としても完全ローカルで小さめの整文モデルを使う方式を用意している。
クラウド処理は、音声と整文ステップの両方をリモートAPIに送る。古いMacでも高速で、最大かつ最も精度の高いモデルを利用できる。トレードオフはプライバシーだ。書き起こし直後に削除されるとはいえ、あなたの音声はデバイスから外に出る。
多くの人にとっては「Whisperはローカル、整文はクラウド」が妥当な既定値だ。医療記録、法的文書、社内情報など機微なデータを扱う人には、わずかな品質低下を許容してでも完全ローカルにする価値がある。良いアプリなら、録音単位の選択や既定値の設定ができる。
AIディクテーションが今でもつまずくところ
正直な話をしよう。パイプラインは優秀だ。完璧ではない。
同音異義語はいまも誤る。 英語の「their」「there」「they're」はほとんどの場合正しく当てるが、常にとはいかない。整文工程が文脈から拾ってくれることが多いが、周辺の文があいまいだと取りこぼす。
固有名詞や専門用語は当たり外れがある。 Whisperは一般的な名前やテック用語の多くを学習しているが、専門性が高くなると崩れる。医薬品名、コードライブラリ名、同僚の珍しい姓などだ。プロンプトに組み込めるカスタム辞書を用意しているアプリもある。
騒がしい環境では精度が一気に落ちる。 Whisperはカフェ程度の雑音には驚くほどよく対応するが、すぐ近くで電話が鳴ったり誰かが話していたりすると、書き起こしから単語が抜け落ちる。
長い独白では話が逸れる。 モデルは10〜30秒のひと区切りで非常に優秀だ。90秒を超えるあたりから、文脈を見失ったり、断片を繰り返したり、短いフレーズを飛ばしたりすることがある。対策は単純で、録音を区切って止めたり再開したりするだけだ。
これらの制約は使い始めの時期には意識しておきたい。どれも、把握していれば致命傷にはならない。選択肢を比較したいなら、Mac向け音声テキスト変換アプリのおすすめガイドで主要アプリの取り扱いを解説している。
今日からMacでAI音声ディクテーションを使い始める方法
実践的なステップは3つ。順番どおりに。
1. 1週間、毎日ディクテーションするタスクを1つだけ決める。 入門にはメールが向いている。タイピングと発話の置き換えがいちばん効くからだ(どのみち書く前に考えるはず)。最初から何でもかんでも口述しようとしない。続かない。
2. 誰もいない場所で話すことに慣れる。 静かな部屋で声に出すと、最初の数回は妙な気分になる。だいたい4日で消える。
3. アプリを1つ選んで使い込む。 Apple純正のディクテーションから、オープンソースのWhisperツール、フルパイプラインのアプリまで、価格帯ごとに良い選択肢がある。先ほど紹介した「書き起こして整文して貼り付ける」流れを求めるなら、Voicrがまさにそれをやる。FNを押して、話して、貼り付け。書き起こしにはWhisper、整文には強力な言語モデル、そしてカーソルがある場所に合わせて変わるアプリ別の文体ルール。Freeプランは月5,000語まで、クレジットカード不要で使える。
この一連のパイプラインは、ようやくディクテーションが妥協ではなくなるところまで来た。品質を速度と引き換えにする必要はない。両方手に入る。難しいのは、タイピングをやめると決めることだけだ。