
Mungkin kamu pernah mencoba voice-to-text sekali, menyerah, lalu kembali ke keyboard. Begitulah kebanyakan orang. Anehnya, alasannya biasanya sama sekali bukan karena kata-katanya salah.
Pengenalan suara sudah akurat sejak bertahun-tahun lalu. Model modern mentranskripsikan ucapan yang jernih dengan akurasi sekitar 95%. Alasan dikte tetap terasa percuma adalah karena transkrip akurat dari cara kamu bicara yang sebenarnya itu berantakan. Large language model adalah bagian yang memperbaiki hal itu, dan mereka mengubah untuk apa voice-to-text berguna.
Selama hampir sepanjang sejarahnya, voice-to-text dinilai dari satu hal: apakah kata-katanya benar? Ternyata itu pertanyaan yang salah. Membuat kata-kata jadi benar tidak pernah menjadi penghalang antara kamu dan menulis dengan suara. Inilah yang sebenarnya berubah.
Voice-to-text tidak pernah jadi masalah transkripsi
Selama puluhan tahun, setiap tim pengenalan suara mengejar angka yang sama: word error rate, atau WER. Angka ini menghitung berapa banyak kata yang salah dikenali sistem. Makin rendah makin bagus, dan seluruh bidang ini dioptimalkan untuk itu.
Mereka sebagian besar berhasil. Whisper dari OpenAI mentranskripsikan audio jernih dengan word error rate sekitar 2,7%. Pada rekaman dunia nyata yang lebih berantakan, seperti rapat atau kafe atau panggilan telepon, angkanya mendekati 8 hingga 12%. Transkripsi manusia berada di kisaran 4 hingga 6%. Selisihnya kecil dan terus menyempit.
Jadi akurasi sudah cukup terpecahkan. Tapi tanyakan kepada siapa pun yang berhenti menggunakan dikte pada 2018 kenapa mereka berhenti, dan hampir tidak ada yang bilang "terlalu banyak typo." Mereka bilang terasa kaku, atau hasilnya butuh begitu banyak pembersihan sampai tidak sepadan dengan usahanya.
Itulah petunjuknya. Hambatannya tidak pernah ada di transkripsi. Hambatannya ada di semua hal yang terjadi setelah kata-katanya sudah benar.
Seperti apa transkrip mentah dari ucapanmu
Inilah yang tidak pernah diperingatkan kepadamu: kamu tidak bicara dalam kalimat yang rapi. Tidak ada yang begitu.
Saat kamu bicara secara alami, kamu mundur, mengulang, menggantung, dan menyelipkan "em" dan "kayak" dan "kamu tahu lah." Otakmu menyunting semua itu secara spontan dan kamu tidak pernah menyadarinya. Mesin transkripsi menyadari semuanya dan menulis setiap detailnya.
Misalkan kamu mendikte pesan singkat ke rekan kerja. Dari transkriber murni, hasilnya kembali seperti ini:
*"oke jadi em aku mau nanya soal soal yang kemarin itu, laporannya, bisa nggak kamu eh kirim kalau sempat, nggak buru-buru sih"*
Setiap katanya benar. Tapi juga tidak bisa dipakai. Kamu bakal menghabiskan lebih banyak waktu untuk membenahinya daripada waktu yang kamu hemat dengan mengucapkannya. Inilah momen persis ketika kebanyakan orang menyerah dari dikte untuk selamanya.
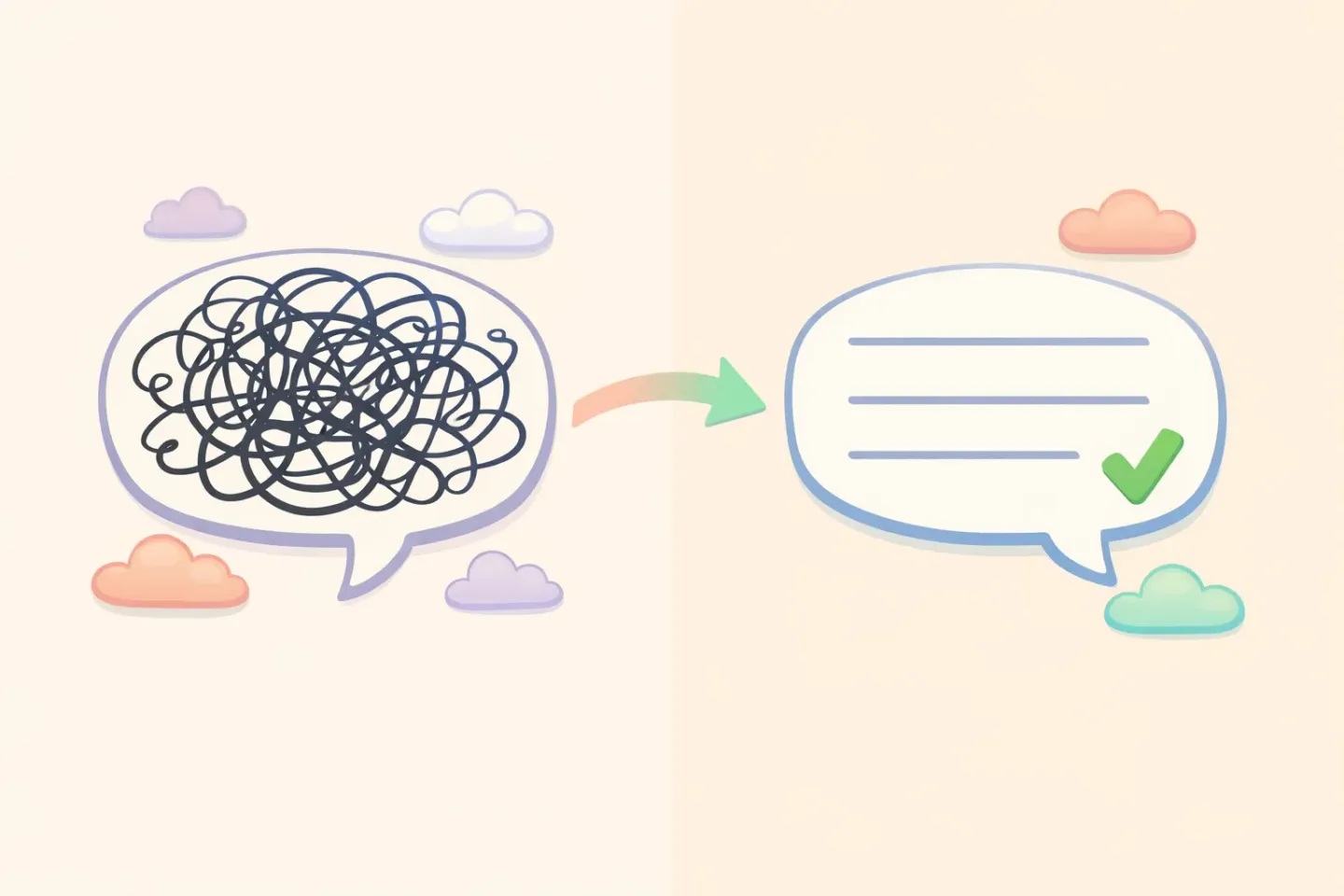
Apa yang sebenarnya ditambahkan large language model
Transkriber menjawab satu pertanyaan: bunyi apa yang dikeluarkan orang ini? Language model menjawab pertanyaan yang berbeda: apa maksud orang ini, dan bagaimana seharusnya ini dibaca?
Pertanyaan kedua itulah intinya. Sebuah LLM mengambil transkrip yang berantakan dan menulis ulangnya seperti yang dilakukan editor yang cermat. Ia membuang kata pengisi, menyelesaikan kalimat setengah jadi, memperbaiki tata bahasa, dan menjaga makna tetap utuh. Pesan di atas menjadi:
*"Hai, bisa kirim laporan kemarin kalau sempat? Tidak buru-buru."*
Maksud yang sama, terbaca sekali jalan. Transkripsinya tidak jadi lebih baik di sini. Yang berubah adalah lapisan kedua yang duduk di atasnya, melakukan penyuntingan yang seharusnya kamu lakukan sendiri.
Ini lebih dari sekadar trik produk. Para peneliti mempelajarinya secara langsung. Sebuah makalah 2024 dari konferensi ACM CHI bernama Rambler menemukan bahwa membiarkan orang bicara secara longgar dan menggunakan LLM untuk membentuk ulang "intisarinya" menghasilkan tulisan yang lebih baik dengan usaha lebih kecil dibandingkan mengetik atau dikte mentah. Bicara adalah cara kita berpikir dengan lantang. Model menangani bagian yang biasanya dilewatkan otak kita.
Penelitian lain mengarah ke hal yang sama. Studi tentang penyempurnaan transkrip berbasis LLM menunjukkan bahwa menjalankan ucapan lewat language model setelah pengenalan suara mengurangi kesalahan dan meningkatkan keterbacaan, terutama untuk homofon dan frasa yang bergantung konteks yang tidak bisa diurai sendiri oleh transkriber biasa.
Konteks adalah setengahnya yang lain
Membersihkan transkrip adalah tugas pertama. Mengetahui jenis tulisan apa yang kamu inginkan adalah tugas kedua, dan di situlah hal-hal jadi menarik.
"Kirim deck-nya sebelum hari ini berakhir" cocok untuk pesan Slack ke rekan satu tim. Terlalu tumpul untuk email klien. Kata-katanya tidak masalah; nada-nya yang meleset. Sebuah language model bisa membaca situasi itu dan menyesuaikan nada, karena ia memahami konteks, bukan cuma bunyi.
Dalam praktiknya, kalimat lisan yang sama bisa keluar santai di satu aplikasi dan rapi di aplikasi lain. Kamu tidak mengubah cara bicaramu. Model mengubah cara menulisnya, berdasarkan ke mana teks itu akan dituju.
Inilah yang persis dilakukan oleh Smart Rules milik Voicr. Kamu atur sekali nada santai untuk Slack dan nada formal untuk email, lalu Voicr menyadari aplikasi mana yang sedang kamu pakai dan menerapkan gaya yang tepat secara otomatis. Tahan FN, ucapkan saja, dan versi yang mendarat di clipboard-mu sudah pas dengan tempat kamu akan menempelkannya.
Pergeseran nyatanya: kamu berhenti bicara ke komputer
Dikte zaman dulu memaksamu berakting. Kamu harus bicara dalam kalimat yang sudah jadi, mengucapkan "koma" dan "paragraf baru" dengan lantang, dan meninggalkan kebiasaan bicaramu yang normal. Kamu melakukan penyuntingan di kepalamu, secara real-time, sambil bicara. Itu melelahkan, dan itulah kenapa tidak pernah bertahan.
Voice-to-text berbasis LLM mengangkat tugas itu dari pundakmu. Kamu boleh ngalor-ngidul. Kamu boleh berubah pikiran di tengah kalimat. Kamu boleh bicara seperti saat menjelaskan sesuatu ke teman, dan versi bersihnya tetap muncul.
Kedengarannya hal kecil. Padahal itulah seluruh perbedaan antara mengoperasikan alat dan sekadar berpikir dengan lantang.
Soal kecepatan juga nyata. Kebanyakan orang bicara sekitar 150 kata per menit dan mengetik sekitar 40. Sebuah studi Stanford menemukan bahwa input suara di ponsel tiga kali lebih cepat daripada mengetik, dengan lebih sedikit kesalahan. Tapi kecepatan berhenti jadi daya tarik utama begitu hasilnya bagus. Daya tarik sesungguhnya adalah kamu tidak lagi kehilangan alur pikir gara-gara keyboard. Kami mengupas hitungan itu di kenapa suaramu lebih cepat daripada keyboard.
Di mana LLM masih salah menangani voice-to-text
Ini benar-benar lebih baik, bukan sihir. Kecerdasan yang sama yang membersihkan teksmu juga bisa kebablasan, dan ada baiknya tahu di mana.
Ia bisa mengubah maksudmu. Saat model "memperbaiki" kalimat, kadang ia menghaluskan detail yang kamu inginkan atau salah menebak maksudmu. Makin teknis atau tidak biasa frasamu, makin tinggi risikonya. Bacalah sekilas apa pun yang penting sebelum kamu mengirimnya.
Nama dan istilah teknis masih bikin tersandung. Transkripsi menangani kata umum dengan baik dan kesulitan dengan nama diri, nama produk, dan istilah khusus. Sebuah model bisa menebak dari konteks, tapi ia akan dengan percaya diri menyalah-tuliskan nama belakang rekanmu.
Homofon belum sepenuhnya terpecahkan. Pasangan kata yang terdengar mirip biasanya tepat karena konteks membantu, tapi tidak setiap saat.
Ia menambah sedikit jeda latensi. Transkriber murni nyaris instan. Menjalankan model kedua untuk memoles butuh waktu mulai dari sepersekian detik hingga beberapa detik. Sepadan demi kualitas, tapi bukan tanpa biaya.
Tidak ada satu pun dari ini yang jadi pemecah kesepakatan begitu kamu tahu keberadaannya. Inilah alasan kebiasaan membaca-sebelum-kirim tetap berguna. Kalau kamu mau gambaran lengkap soal bagaimana pipeline ini berjalan dari ujung ke ujung, kami sudah menulis panduan langkah demi langkah dikte suara AI di Mac.

Apa artinya ini bagi cara kamu menulis
Model mental yang layak dipegang adalah bahwa voice-to-text kini adalah dua alat yang ditumpuk jadi satu:
1. Lapisan transkripsi yang mengubah bunyi menjadi kata yang akurat. 2. Lapisan bahasa yang mengubah kata-kata itu menjadi tulisan yang benar-benar enak dibaca.
Transkripsi murni tetap pilihan yang tepat saat kamu butuh catatan persis. Wawancara, catatan hukum, apa pun yang setiap "em"-nya penting. Untuk yang lain, seperti email, pesan, dokumen, dan catatan, lapisan pemolesanlah yang membuat bicara lebih cepat daripada mengetik, bukannya cuma lebih berantakan.
Jadi ketika kamu memilih sebuah alat, pertanyaan sebenarnya bukan "seberapa akurat transkripsinya." Kebanyakan sudah mendekati sekarang. Pertanyaannya adalah "seberapa bagus lapisan di atasnya." Perbandingan aplikasi voice-to-text terbaik untuk Mac milik kami menguraikan mana saja yang melakukan bagian itu dengan baik.
Cara mencoba voice-to-text yang dipoles LLM
Cara tercepat merasakan perbedaannya adalah mendikte email berikutnya alih-alih mengetiknya, lalu lihat apa yang muncul di draf. Itu tidak akan jadi transkrip mentah yang kamu ingat dari bertahun-tahun lalu. Itu akan terbaca seolah kamu menulisnya di hari yang baik.
Kalau kamu mau itu tanpa harus menyambung-nyambung beberapa alat, Voicr melakukan kedua lapisan dalam satu langkah. Tahan FN, bicara sesukamu, lepas, dan teks yang sudah dipoles mendarat di clipboard-mu siap ditempel. Voicr memakai Whisper untuk transkripsi dan sebuah language model untuk pembersihan, dengan gaya per-aplikasi agar nadanya pas di mana pun kamu menulis. Tier gratisnya 5.000 kata per bulan, tanpa kartu kredit.
Voice-to-text akhirnya bekerja seperti seharusnya sejak dulu. Bukan karena mesin jadi lebih jago mendengarmu, tapi karena mereka akhirnya jadi jago memahami apa yang kamu maksud.