
Du testade förmodligen röst-till-text en gång, gav upp och gick tillbaka till tangentbordet. De flesta gjorde det. Det märkliga är att det oftast inte hade något med att orden kom ut fel att göra.
Taligenkänning blev träffsäker för flera år sedan. Moderna modeller transkriberar rent tal med ungefär 95 % träffsäkerhet. Anledningen till att diktering ändå kändes värdelös är att en korrekt transkription av hur du faktiskt pratar är ett enda virrvarr. Stora språkmodeller är pusselbiten som löste det, och de förändrade vad röst-till-text faktiskt är bra på.
Under större delen av sin historia bedömdes röst-till-text efter en enda sak: fick den orden rätt? Det visade sig vara fel fråga. Att få orden rätt var aldrig det som stod mellan dig och att skriva med rösten. Här är vad som faktiskt förändrades.
Röst-till-text var aldrig ett transkriptionsproblem
I decennier jagade varje taligenkänningsteam samma siffra: word error rate, eller WER. Den räknar hur många ord systemet får fel. Lägre är bättre, och hela fältet optimerade för det.
De vann för det mesta. OpenAI:s Whisper transkriberar rent ljud med ungefär 2,7 % word error rate. På stökigare inspelningar från verkligheten, som ett möte, ett kafé eller ett telefonsamtal, ligger den närmare 8 till 12 %. Mänskliga transkriberare landar runt 4 till 6 %. Gapet är litet och krymper fortfarande.
Så träffsäkerheten löstes, mer eller mindre. Men fråga vem som helst som slutade diktera 2018 varför de gav upp, och nästan ingen säger "för många stavfel". De säger att det kändes klumpigt, eller att resultatet behövde så mycket städning att det inte var värt besväret.
Det är just det som avslöjar saken. Flaskhalsen var aldrig transkriptionen. Det var allt som händer efter att orden redan är korrekta.
Så här ser en rå transkription av ditt tal ut
Här är vad ingen varnar dig för: du pratar inte i rena meningar. Ingen gör det.
När du pratar naturligt backar du, börjar om, tappar tråden och slänger in "öh" och "liksom" och "du vet". Din hjärna redigerar bort allt det i farten utan att du märker något. En transkriptionsmotor märker allt och skriver ner varenda bit av det.
Säg att du dikterar ett snabbt meddelande till en kollega. Ur en ren transkriberare kommer det tillbaka så här:
*"okej så öh jag ville stämma av om det det där från igår, rapporten, kan du eh skicka över den när du får en sekund, ingen brådska eller så"*
Varje ord är korrekt. Det är också oanvändbart. Du skulle lägga mer tid på att fixa det än du sparade på att prata in det. Det är precis i det här ögonblicket som de flesta gav upp dikteringen för gott.
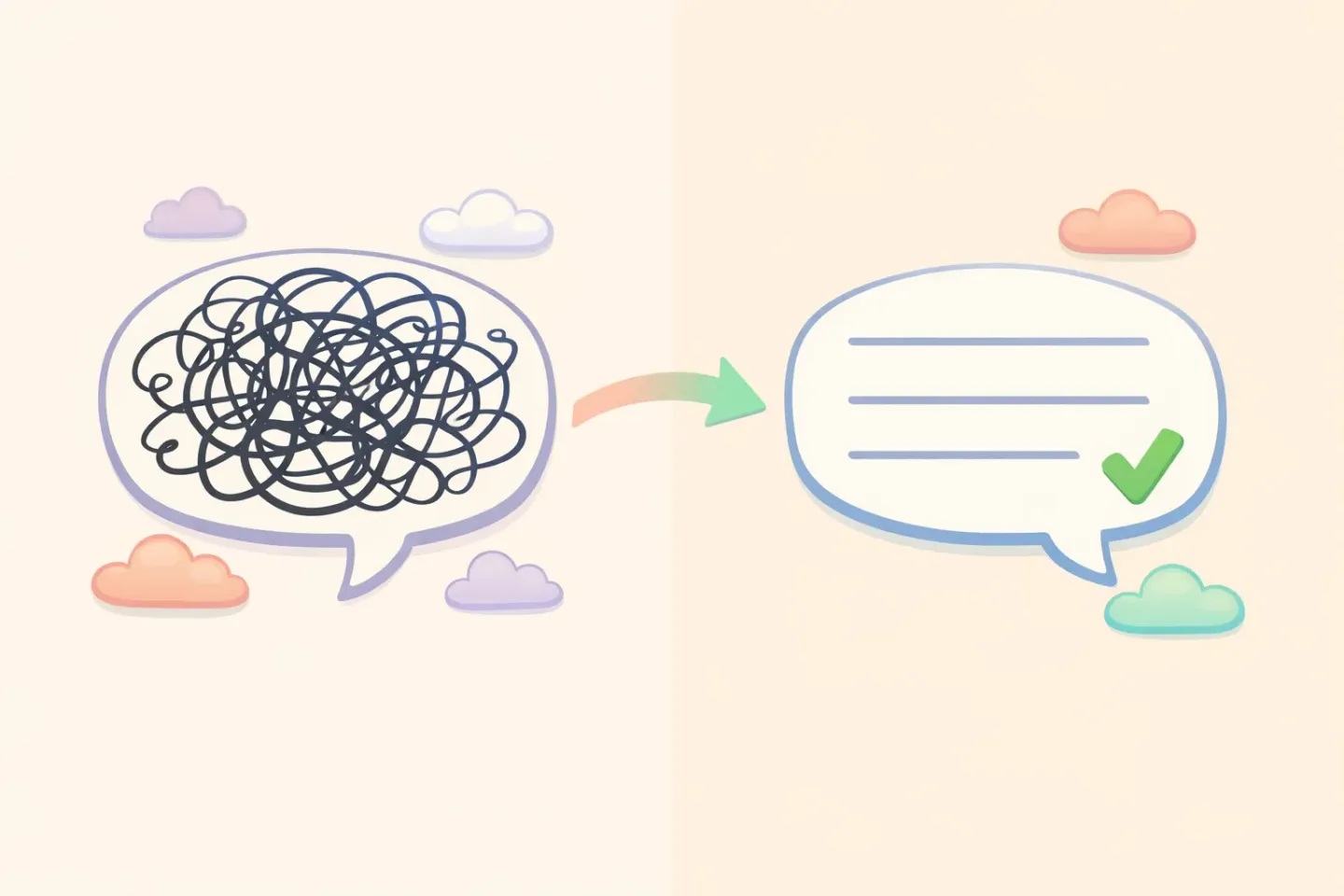
Vad stora språkmodeller faktiskt tillför
En transkriberare svarar på en fråga: vilka ljud gjorde den här personen? En språkmodell svarar på en annan: vad menade den här personen, och hur borde det läsas?
Den andra frågan är hela poängen. En LLM tar den stökiga transkriptionen och skriver om den så som en noggrann redaktör skulle göra. Den tar bort utfyllnadsorden, avslutar dina halva meningar, fixar grammatiken och behåller din mening intakt. Meddelandet ovan blir:
*"Hej, kan du skicka över gårdagens rapport när du får en stund? Ingen brådska."*
Samma avsikt, läsbart vid första genomläsningen. Transkriptionen blev inte bättre här. Det som ändrades är det andra lagret ovanpå, som gör redigeringen du annars skulle ha gjort själv.
Det här är mer än ett produkttrick. Forskare studerar det direkt. En artikel från 2024 vid ACM:s CHI-konferens kallad Rambler visade att om man låter folk prata fritt och använder en LLM för att forma om "kärnan" så ger det bättre text med mindre ansträngning än att skriva eller diktera rått. Att prata är hur vi tänker högt. Modellen sköter den del som våra hjärnor vanligtvis hoppar över.
Annan forskning pekar åt samma håll. Studier av LLM-baserad förfining av transkriptioner visar att om man kör tal genom en språkmodell efter igenkänningen så minskar felen och läsbarheten förbättras, särskilt för homonymer och kontextberoende fraser som en vanlig transkriberare inte kan reda ut på egen hand.
Kontexten är den andra halvan
Att städa upp en transkription är det första jobbet. Att veta vilken sorts text du var ute efter är det andra, och det är där det blir intressant.
"Skicka mig presentationen innan dagens slut" funkar för ett Slack-meddelande till en kollega. Det är för burdust för ett mejl till en kund. Orden är okej; tonen är fel. En språkmodell kan läsa av den situationen och justera tonen, eftersom den förstår kontext, inte bara ljud.
I praktiken kan samma talade mening komma ut avslappnad i en app och putsad i en annan. Du ändrar inte hur du pratar. Modellen ändrar hur den skriver, beroende på vart texten är på väg.
Det är precis vad Voicrs Smart Rules gör. Du ställer in en avslappnad ton för Slack och en formell för mejl en gång, och Voicr märker vilken app du är i och tillämpar rätt stil automatiskt. Håll inne FN, säg det du vill säga, och versionen som hamnar i ditt urklipp passar redan dit du är på väg att klistra in.
Den verkliga förändringen: du slutar prata med en dator
Gammaldags diktering tvingade dig att prestera. Du var tvungen att prata i färdiga meningar, säga "komma" och "nytt stycke" högt och släppa dina vanliga talvanor. Du gjorde redigeringen i huvudet, i realtid, samtidigt som du pratade. Det var utmattande, vilket är varför det aldrig fastnade.
LLM-baserad röst-till-text tar det jobbet av dina axlar. Du får svamla. Du får ändra dig mitt i en mening. Du får prata på samma sätt som du skulle förklara något för en vän, och den rena versionen dyker upp ändå.
Det låter som en liten sak. Det är hela skillnaden mellan att hantera ett verktyg och att bara tänka högt.
Snabbheten är också verklig. De flesta pratar runt 150 ord i minuten och skriver runt 40. En studie från Stanford visade att röstinmatning på en telefon var tre gånger snabbare än att skriva, med färre fel. Men snabbheten slutade vara den främsta lockelsen när resultatet väl blev bra. Den verkliga lockelsen är att du inte längre tappar tankegången till ditt tangentbord. Vi grävde i den matematiken i varför din röst är snabbare än ditt tangentbord.
Där LLM:er fortfarande får röst-till-text fel
Det här är på riktigt bättre, inte magi. Samma intelligens som städar din text kan också gå för långt, och det är värt att veta var.
Den kan ändra din mening. När en modell "fixar" en mening slätar den ibland bort en detalj du ville ha med eller gissar fel om din avsikt. Ju mer tekniskt eller ovanligt ditt sätt att uttrycka dig är, desto högre är risken. Läs igenom allt viktigt snabbt innan du skickar det.
Namn och fackspråk ställer fortfarande till det. Transkription klarar vanliga ord bra och kämpar med egennamn, produktnamn och specialiserade termer. En modell kan gissa utifrån kontexten, men den kommer självsäkert att stava din kollegas efternamn fel.
Homonymer är inte helt lösta. På svenska landar saker som "de" och "dem" eller "var" och "vart" oftast rätt eftersom kontexten hjälper till, men inte varje gång.
Den lägger till ett ögonblick av fördröjning. En ren transkriberare är nästan omedelbar. Att köra en andra modell för att putsa kostar allt från en bråkdel av en sekund till ett par sekunder. Värt det för kvaliteten, men det är inte gratis.
Inget av detta är dealbreakers när du väl vet att de finns. De är anledningen till att en vana att läsa igenom innan du skickar fortfarande lönar sig. Om du vill ha hela bilden av hur den här pipelinen fungerar från början till slut skrev vi en steg-för-steg-guide till AI-röstdiktering på Mac.

Vad det här betyder för hur du skriver
Den mentala modellen värd att hålla fast vid är att röst-till-text nu är två verktyg staplade på varandra:
1. Ett transkriptionslager som gör ljud till korrekta ord. 2. Ett språklager som gör de orden till text som faktiskt läses väl.
Ren transkription är fortfarande rätt val när du behöver ett exakt protokoll. Intervjuer, juridiska anteckningar, allt där varje "öh" spelar roll. För allt annat, som mejl, meddelanden, dokument och anteckningar, är det putsande lagret det som gör att prata snabbare än att skriva i stället för bara stökigare.
Så när du väljer ett verktyg är den verkliga frågan inte "hur träffsäker är transkriptionen". De flesta ligger nära nu. Frågan är "hur bra är lagret ovanpå". Vår jämförelse av de bästa röst-till-text-apparna för Mac går igenom vilka som gör den delen bra.
Så testar du LLM-putsad röst-till-text
Det snabbaste sättet att känna skillnaden är att diktera ditt nästa mejl i stället för att skriva det, och sedan titta på vad som dyker upp i utkastet. Det blir inte den råa transkriptionen du minns från åratal tillbaka. Det kommer att läsa som om du skrev det på en bra dag.
Om du vill ha det utan att sy ihop verktyg på egen hand gör Voicr båda lagren i ett enda steg. Håll inne FN, prata hur du vill, släpp, och putsad text landar i ditt urklipp redo att klistras in. Den använder Whisper för transkription och en språkmodell för städningen, med stilar per app så att tonen passar var du än skriver. Gratisnivån är 5 000 ord i månaden, inget kreditkort.
Röst-till-text fungerar äntligen så som det alltid borde ha gjort. Inte för att maskinerna blev bättre på att höra dig, utan för att de äntligen blev bra på att förstå vad du menade.