
你大概试过一次语音转文字,然后放弃了,又回到键盘上。大多数人都是这样。奇怪的地方在于,问题通常根本不是识别出来的字错了。
语音识别在几年前就已经很准确了。如今的模型转写干净的语音,准确率大约能到 95%。听写之所以仍然让人觉得没用,是因为把你真实说话的样子原样转写下来,本身就是一团糟。大语言模型正是补上这块短板的那一环,它改变了语音转文字真正擅长的事情。
在它的大半段历史里,语音转文字一直只被一件事衡量:字识别对了没有?后来发现这其实问错了。识别对字,从来不是挡在你和「用嘴写作」之间的那道坎。下面就是真正改变了的东西。
语音转文字从来都不是转写问题
几十年来,每个语音识别团队追的都是同一个数字:词错率(WER)。它衡量系统识别错了多少个词。越低越好,整个领域都在为它优化。
他们基本上赢了。OpenAI 的 Whisper 转写干净的音频,词错率大约只有 2.7%。在更嘈杂的真实录音里,比如开会、咖啡馆或者打电话,它会接近 8% 到 12%。人工速记员大约在 4% 到 6% 之间。差距很小,而且还在继续缩小。
所以准确率算是解决得差不多了。但你去问任何一个在 2018 年放弃听写的人为什么不用了,几乎没有人会说「错字太多」。他们说的是用起来别扭,或者输出还要花太多工夫去清理,根本不值。
这就是关键线索。瓶颈从来不在转写,而在于字都已经识别对了之后的所有环节。
你说话的原始转写稿是什么样子
有件事没人提醒过你:你说话并不是一句句干净利落的。没有人是这样的。
你自然说话时,会回头改、会重新起头、会说到一半没了下文,还会塞进「呃」「就是」「你懂的」这类词。你的大脑会在说的同时把这些全部编辑掉,你自己根本不会察觉。而转写引擎察觉到了一切,并把每一个字都原原本本记了下来。
假设你给同事口述一条快讯。从一个纯转写工具里出来,它会是这样:
*「呃那个我想确认一下那个那个昨天的事,就是那份报告,你能不能呃有空的时候发给我,不急啊随便什么时候」*
每个字都没错,但它根本没法用。你花在修它上的时间,比说出来省下的还多。这正是大多数人彻底放弃听写的那一刻。
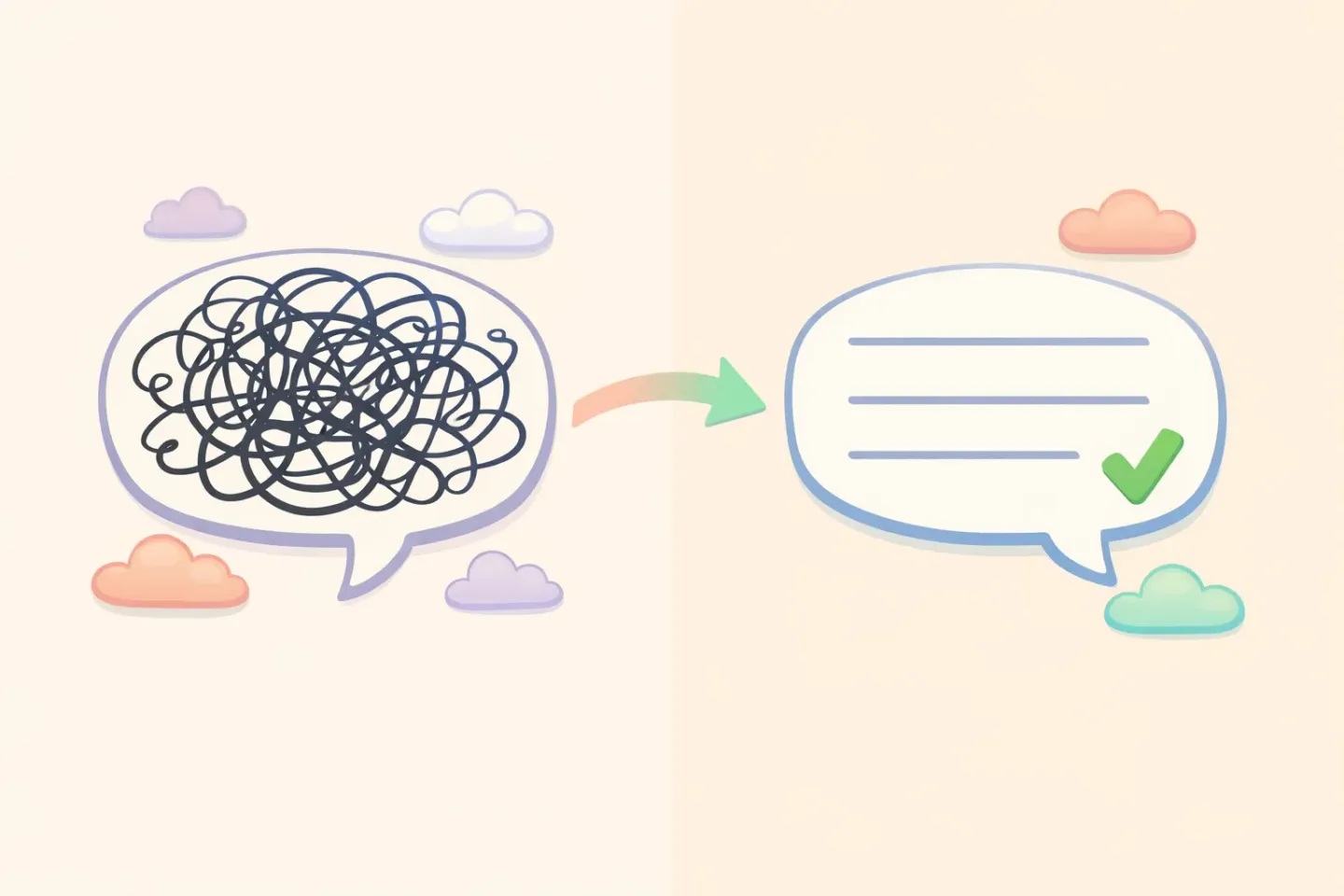
大语言模型究竟补上了什么
转写工具回答的是一个问题:这个人发出了哪些声音?语言模型回答的是另一个问题:这个人想表达什么,以及它读起来该是什么样?
第二个问题才是全部的胜负所在。大语言模型拿到那段杂乱的转写稿,像一位细心的编辑那样把它重写一遍。它去掉语气词,补完你那些没说完的半句话,修好语法,同时保留你的原意。上面那条消息就变成了:
*「你好,方便的时候能把昨天那份报告发我一下吗?不急。」*
意思一样,一遍就能读懂。这里转写本身并没有变好。变了的是叠在它上面的第二层,替你做了那些原本要你自己来做的编辑工作。
这不只是个产品上的小花招,研究者正在直接研究它。2024 年 ACM CHI 会议上一篇名为 Rambler 的论文发现,让人随意松散地说,再用大语言模型重塑其中的「大意」,写出来的东西比打字或原始听写更好,付出的力气也更少。说话是我们边想边表达的方式,模型来处理我们大脑通常会跳过的那一部分。
其他研究指向同一个方向。关于基于大语言模型的转写稿润色的研究表明,在识别之后再让语音经过一个语言模型,能减少错误、提升可读性,尤其是对那些纯转写工具自己搞不定的同音词和依赖上下文的表达。
上下文是另一半
清理转写稿是第一件事。搞清楚你想要哪种文字,是第二件事,而有意思的地方就在这里。
「今天下班前把方案发我」给队友发 Slack 消息没问题,但用在给客户的邮件里就太生硬了。词没毛病,是语气不对。语言模型能读懂这个场景并调整语气,因为它理解的是上下文,而不只是声音。
实际用起来,同一句话在一个应用里出来是随意的,在另一个应用里出来就是讲究的。你说话的方式没变,是模型根据这段文字最终要去哪儿,改变了它落笔的方式。
这正是 Voicr 的 Smart Rules 在做的事。你只需设置一次,给 Slack 配上轻松的语气、给邮件配上正式的语气,Voicr 就会留意你当前在哪个应用里,并自动套用对应的风格。按住 FN,把话说出来,落进你剪贴板里的那个版本,已经契合你接下来要粘贴的地方。
真正的转变:你不再是在跟电脑说话
旧式听写要你「表演」。你得说出完整成形的句子,把「逗号」「另起一段」念出来,还要丢掉自己平时的说话习惯。你是在脑子里一边说一边实时做编辑。这很累人,所以它从来没能坚持下来。
基于大语言模型的语音转文字把这份活儿从你肩上卸了下来。你可以漫无边际地说,可以说到一半改主意,可以像给朋友解释事情那样去说,干净的版本照样会出现。
这听起来像件小事,但它就是「操作一件工具」和「单纯地把想法说出来」之间的全部差别。
速度上的好处也是实打实的。大多数人说话大约每分钟 150 个词,打字大约 40 个词。一项 斯坦福研究发现,在手机上用语音输入比打字快三倍,而且错误更少。但一旦输出质量上去了,速度就不再是主要卖点了。真正的吸引力在于,你不再因为要敲键盘而打断自己的思路。我们在为什么用嘴比用键盘更快里把这笔账算得很细。
大语言模型在语音转文字上仍然会出错的地方
这确实更好了,但它不是魔法。那份能清理你文字的智能,也可能用力过猛,值得了解它会在哪儿越界。
它可能改变你的意思。模型在「修」一个句子时,有时会把你本想保留的某个细节抹平,或者猜错你的意图。你的表达越专业、越不寻常,风险就越高。重要的内容,发出去前都先快速读一遍。
人名和行话仍然会绊倒它。转写处理常用词没问题,但对专有名词、产品名和专业术语就很吃力。模型能靠上下文猜,但它会很自信地把你同事的姓写错。
同音词还没被彻底解决。英语里的「their」「there」和「they're」通常能落对,因为有上下文帮忙,但并不是每次都对。
它会增加一点点延迟。纯转写几乎是即时的。再跑第二个模型来润色,要多花从几分之一秒到一两秒不等的时间。为了质量,这很值,但它不是免费的。
一旦知道这些问题的存在,它们都算不上致命伤。它们正是「发出去前先快速读一遍」这个习惯依然值得保持的原因。如果你想完整了解这条流水线从头到尾是怎么跑的,我们写了一份Mac 上 AI 语音听写的分步指南。

这对你的写作方式意味着什么
值得记住的心智模型是:现在的语音转文字是两件工具叠在一起的:
1. 一个转写层,把声音变成准确的文字。 2. 一个语言层,把这些文字变成真正读得通顺的书面表达。
当你需要一份精确的记录时,纯转写仍然是正确的选择。比如采访、法律记录,以及任何每一个「呃」都重要的场合。除此之外的几乎一切,像邮件、消息、文档和笔记,正是那一层润色让「说」比「打」更快,而不是更乱。
所以挑工具的时候,真正该问的不是「转写有多准」。现在大多数都很接近了。该问的是「上面那一层有多好」。我们这篇Mac 上最好用的语音转文字应用对比,把哪些工具在这件事上做得好讲清楚了。
怎样试试经大语言模型润色的语音转文字
感受这个差别最快的办法,就是下一封邮件别打字,改用口述,然后看看草稿里出现的是什么。它不会是你多年前记忆里那种原始转写稿,而会读起来像你状态好的那天亲手写的。
如果你不想自己东拼西凑地拼工具,Voicr 一步就把两层都做了。按住 FN,想怎么说就怎么说,松手,润色好的文字就落进你的剪贴板,随时可以粘贴。它用 Whisper 做转写,用一个语言模型做清理,还能按应用区分风格,让语气契合你正在写东西的地方。免费档每月 5,000 个词,无需信用卡。
语音转文字终于按它本该有的样子运转了。不是因为机器更会「听」你说话,而是因为它们终于学会了理解你想表达的意思。