
아마 한 번쯤 음성-텍스트 변환을 써 보다가 포기하고 다시 키보드로 돌아간 적이 있을 겁니다. 대부분이 그랬죠. 이상한 건, 그게 보통 단어가 틀리게 받아 적혀서 그런 게 아니었다는 점입니다.
음성 인식은 이미 수년 전에 정확해졌습니다. 요즘 모델은 깨끗한 음성을 약 95% 정확도로 받아 적습니다. 그런데도 받아쓰기가 여전히 쓸모없게 느껴졌던 이유는, 사람이 실제로 말하는 방식을 정확히 옮긴 글이 엉망진창이기 때문입니다. 대규모 언어 모델이 바로 그 문제를 고친 부분이고, 음성-텍스트 변환이 어디에 쓸모 있는지를 바꿔 놓았습니다.
역사 대부분 동안 음성-텍스트 변환은 단 하나의 기준으로 평가받았습니다. 단어를 제대로 받아 적었는가? 그런데 그건 잘못된 질문이었습니다. 단어를 제대로 받아 적는 일은 애초에 당신과 '음성으로 글쓰기' 사이를 가로막던 장벽이 아니었습니다. 실제로 무엇이 바뀌었는지 살펴보겠습니다.
음성-텍스트 변환은 애초에 받아쓰기 문제가 아니었다
수십 년 동안 모든 음성 인식 팀은 같은 숫자를 쫓았습니다. 바로 단어 오류율, 즉 WER입니다. 시스템이 단어를 몇 개나 틀리는지를 세는 지표죠. 낮을수록 좋고, 업계 전체가 이 수치를 낮추는 데 매달렸습니다.
그들은 대체로 이겼습니다. OpenAI의 Whisper는 깨끗한 오디오를 약 2.7%의 단어 오류율로 받아 적습니다. 회의실이나 카페, 전화 통화처럼 더 지저분한 실제 녹음에서는 8~12%에 가깝게 올라갑니다. 사람 속기사는 약 4~6% 수준입니다. 격차는 작고 지금도 계속 좁혀지고 있습니다.
그래서 정확도는 어느 정도 해결됐습니다. 그런데 2018년에 받아쓰기를 그만둔 사람에게 왜 그만뒀냐고 물어보면, "오타가 너무 많아서"라고 답하는 사람은 거의 없습니다. 다들 어딘가 어색했다고, 혹은 결과물을 다듬는 데 손이 너무 많이 가서 그럴 가치가 없었다고 말합니다.
바로 그게 핵심 단서입니다. 병목은 받아쓰기에 있던 적이 없습니다. 병목은 단어가 이미 정확히 적힌 뒤에 벌어지는 모든 일에 있었습니다.
당신이 말한 그대로 받아 적은 글은 어떻게 생겼나
아무도 미리 말해 주지 않는 사실이 있습니다. 사람은 깔끔한 문장으로 말하지 않습니다. 누구도 그렇게 말하지 않죠.
자연스럽게 말할 때 우리는 되돌아가고, 다시 시작하고, 말끝을 흐리고, "음", "그러니까", "있잖아" 같은 말을 끼워 넣습니다. 우리 뇌는 그 모든 걸 즉석에서 편집해 버려서 본인은 전혀 눈치채지 못합니다. 그런데 받아쓰기 엔진은 그 전부를 알아채고 하나도 빠짐없이 적어 버립니다.
동료에게 짧은 메시지를 음성으로 받아쓴다고 해 봅시다. 순수 받아쓰기 엔진을 거치면 이렇게 돌아옵니다.
*"어 그러니까 음 어제 그 그거에 대해서 좀 확인하고 싶었는데, 그 보고서 말이야, 시간 날 때 어 좀 보내 줄 수 있어, 급한 건 아니고 뭐 그래"*
단어는 전부 맞습니다. 그런데 그대로는 못 씁니다. 그걸 고치는 데 말로 아낀 시간보다 더 많은 시간이 들 겁니다. 바로 이 순간에 대부분이 받아쓰기를 영영 포기했습니다.
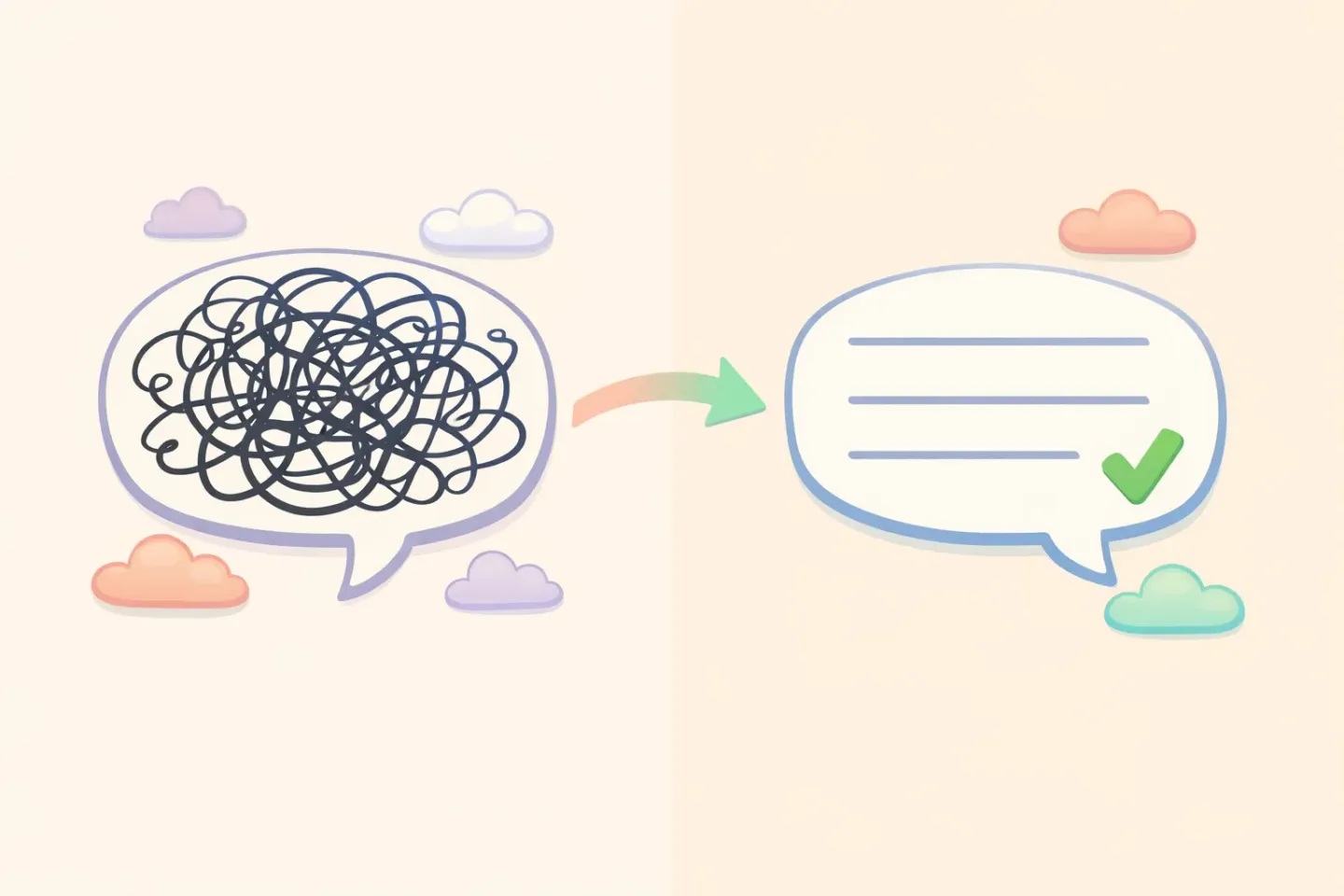
대규모 언어 모델이 실제로 더해 주는 것
받아쓰기 엔진은 한 가지 질문에 답합니다. 이 사람이 어떤 소리를 냈는가? 언어 모델은 다른 질문에 답합니다. 이 사람이 무엇을 말하려 했고, 그게 어떻게 읽혀야 하는가?
그 두 번째 질문이 모든 것을 가릅니다. LLM은 지저분한 받아쓰기 결과를 가져다가 꼼꼼한 편집자처럼 다시 씁니다. 군더더기를 덜어 내고, 미완성 문장을 마무리하고, 문법을 고치면서도 당신의 의도는 그대로 살립니다. 앞의 메시지는 이렇게 바뀝니다.
*"안녕하세요, 시간 되실 때 어제 그 보고서 좀 보내 주실 수 있을까요? 급하지는 않습니다."*
의도는 같고, 한 번에 읽힙니다. 여기서 받아쓰기 자체가 더 좋아진 건 아닙니다. 바뀐 건 그 위에 얹힌 두 번째 계층입니다. 원래라면 당신이 직접 했을 편집을 대신 해 주는 것이죠.
이건 단순한 제품 트릭이 아닙니다. 연구자들이 직접 이 현상을 파고들고 있습니다. ACM CHI 학회에서 발표된 2024년 논문 Rambler는, 사람이 느슨하게 말하게 두고 LLM이 그 "요지"를 다시 빚어내게 하면, 타이핑이나 순수 받아쓰기보다 더 적은 노력으로 더 나은 글이 나온다는 것을 발견했습니다. 말하기는 우리가 소리 내어 생각하는 방식입니다. 모델은 우리 뇌가 평소에 건너뛰는 부분을 맡아 줍니다.
다른 연구들도 같은 방향을 가리킵니다. LLM 기반 받아쓰기 정제에 관한 연구들을 보면, 인식 이후 음성을 언어 모델에 다시 통과시키면 오류가 줄고 가독성이 좋아진다고 합니다. 특히 순수 받아쓰기 엔진 혼자서는 가려내기 힘든 동음이의어와 맥락 의존적인 표현에서 효과가 큽니다.
나머지 절반은 맥락이다
받아쓰기 결과를 다듬는 것이 첫 번째 일입니다. 당신이 어떤 종류의 글을 원했는지 아는 것이 두 번째 일이고, 바로 여기서부터 흥미로워집니다.
"오늘 안에 자료 보내 주세요"는 동료에게 보내는 Slack 메시지로는 괜찮습니다. 하지만 고객에게 보내는 이메일로는 너무 무뚝뚝합니다. 단어는 멀쩡한데 어조가 어긋난 것이죠. 언어 모델은 그 상황을 읽고 어조를 맞출 수 있습니다. 소리만이 아니라 맥락을 이해하기 때문입니다.
실제로 똑같이 말한 문장이 어떤 앱에서는 캐주얼하게, 다른 앱에서는 격식 있게 나올 수 있습니다. 당신은 말하는 방식을 바꾸지 않습니다. 모델이 그 글이 향하는 곳에 맞춰 쓰는 방식을 바꿉니다.
Voicr의 Smart Rules가 하는 일이 바로 이것입니다. Slack에는 편안한 어조를, 이메일에는 격식 있는 어조를 한 번만 설정해 두면, Voicr가 당신이 어느 앱에 있는지 알아채고 알맞은 스타일을 자동으로 적용합니다. FN을 누른 채 할 말을 하면, 클립보드에 들어오는 버전은 이미 붙여 넣을 곳에 딱 맞게 정리되어 있습니다.
진짜 변화: 컴퓨터에게 말 거는 일을 그만두게 된다
옛날 받아쓰기는 일종의 연기를 요구했습니다. 완성된 문장으로 말해야 했고, "쉼표"나 "줄 바꿈"을 소리 내어 말해야 했으며, 평소의 말버릇을 버려야 했습니다. 말하면서 동시에 머릿속에서 실시간으로 편집을 하고 있었던 셈이죠. 진이 빠지는 일이었고, 그래서 결국 자리 잡지 못했습니다.
LLM 기반 음성-텍스트 변환은 그 일을 당신 손에서 가져갑니다. 두서없이 말해도 됩니다. 문장 중간에 마음을 바꿔도 됩니다. 친구에게 무언가를 설명하듯 말해도, 깔끔하게 정리된 버전이 알아서 나타납니다.
사소한 일처럼 들릴 수 있습니다. 하지만 이것이 도구를 조작하는 것과 그냥 소리 내어 생각하는 것 사이의 결정적인 차이입니다.
속도 또한 분명한 이점입니다. 대부분의 사람은 1분에 약 150단어를 말하고 약 40단어를 타이핑합니다. 스탠퍼드 연구에 따르면 휴대폰에서 음성 입력은 타이핑보다 세 배 빠르고 오류도 더 적었습니다. 하지만 결과물이 좋아지자 속도는 더 이상 주된 매력이 아니게 됐습니다. 진짜 매력은 키보드에 생각의 흐름을 빼앗기지 않게 된다는 점입니다. 이 계산은 당신의 목소리가 키보드보다 빠른 이유에서 자세히 다뤘습니다.
LLM이 여전히 음성-텍스트 변환에서 헛디디는 지점
이건 진짜로 더 나아진 것이지, 마법이 아닙니다. 당신의 글을 다듬어 주는 바로 그 지능이 도를 넘을 수도 있는데, 어디서 그러는지 알아 두면 좋습니다.
의미를 바꿔 버릴 수 있습니다. 모델이 문장을 "고칠" 때, 당신이 살리고 싶었던 디테일을 매끄럽게 지워 버리거나 의도를 잘못 추측하기도 합니다. 표현이 전문적이거나 평범하지 않을수록 위험은 커집니다. 중요한 내용은 보내기 전에 한 번 빠르게 읽어 보세요.
이름과 전문 용어는 여전히 걸림돌입니다. 받아쓰기는 흔한 단어는 잘 처리하지만 고유 명사, 제품명, 전문 용어에서는 헤맵니다. 모델이 맥락으로 추측할 수는 있지만, 동료의 성을 자신만만하게 틀리게 적어 놓기도 합니다.
동음이의어가 완전히 해결된 건 아닙니다. 영어의 "their", "there", "they're"는 맥락 덕분에 대개 맞게 들어가지만, 매번 그런 건 아닙니다.
약간의 지연이 더해집니다. 순수 받아쓰기 엔진은 거의 즉각적입니다. 다듬기 위해 두 번째 모델을 돌리면 1초의 몇 분의 일에서 길게는 몇 초까지 걸립니다. 품질을 생각하면 그만한 값어치가 있지만, 공짜는 아닙니다.
이 중 어느 것도 존재한다는 걸 알고 나면 치명적인 결함은 아닙니다. 오히려 보내기 전에 한 번 빠르게 읽어 보는 습관이 여전히 도움이 되는 이유죠. 이 파이프라인이 처음부터 끝까지 어떻게 돌아가는지 전체 그림이 궁금하다면, Mac에서 AI 음성 받아쓰기를 단계별로 정리한 가이드를 따로 써 두었습니다.

이것이 당신의 글쓰기에 의미하는 것
기억해 둘 만한 사고 모델은, 이제 음성-텍스트 변환이 두 도구를 포개 놓은 것이라는 점입니다.
1. 소리를 정확한 단어로 바꾸는 받아쓰기 층. 2. 그 단어들을 실제로 잘 읽히는 글로 바꾸는 언어 층.
정확한 기록이 필요할 때는 여전히 순수 받아쓰기가 맞는 선택입니다. 인터뷰, 법률 메모, "음" 하나하나가 중요한 모든 경우가 그렇죠. 그 외의 모든 것, 이를테면 이메일, 메시지, 문서, 메모에서는 다듬기 층이 있어야 말하기가 그저 더 지저분한 게 아니라 타이핑보다 빠른 일이 됩니다.
그래서 도구를 고를 때 진짜 던져야 할 질문은 "받아쓰기가 얼마나 정확한가"가 아닙니다. 이제 대부분 엇비슷합니다. 질문은 "위에 얹힌 층이 얼마나 좋은가"입니다. Mac용 음성-텍스트 변환 앱 비교에서 어떤 앱이 그 부분을 잘하는지 정리해 두었습니다.
LLM으로 다듬는 음성-텍스트 변환을 직접 써 보는 법
차이를 가장 빠르게 느끼는 방법은, 다음 이메일을 타이핑하는 대신 음성으로 받아쓴 다음 초안에 무엇이 나타나는지 보는 것입니다. 몇 년 전에 기억하던 그 날것의 받아쓰기 결과가 아닐 겁니다. 컨디션 좋은 날 직접 쓴 것처럼 읽힐 겁니다.
도구를 이리저리 이어 붙이지 않고 그걸 누리고 싶다면, Voicr가 두 층을 한 번에 처리합니다. FN을 누른 채 원하는 대로 말하고 손을 떼면, 다듬어진 텍스트가 바로 붙여 넣을 수 있게 클립보드에 들어옵니다. 받아쓰기에는 Whisper를, 다듬기에는 언어 모델을 쓰며, 앱별 스타일 덕분에 어디에 쓰든 어조가 잘 맞습니다. 무료 등급은 월 5,000단어이고 신용카드도 필요 없습니다.
음성-텍스트 변환이 드디어 처음부터 그래야 했던 방식대로 작동합니다. 기계가 당신의 말을 더 잘 듣게 되어서가 아니라, 당신이 무엇을 말하려 했는지를 드디어 잘 이해하게 되었기 때문입니다.